1
Explore
Sample many low-cost reasoning trajectories with a masked diffusion language model to preserve diversity and broaden the search space.
Overview
Reasoning with large language models often benefits from generating multiple chains of thought, but common aggregation strategies usually operate at the whole-trajectory level. That means they throw away useful intermediate reasoning from paths that are only partially correct.
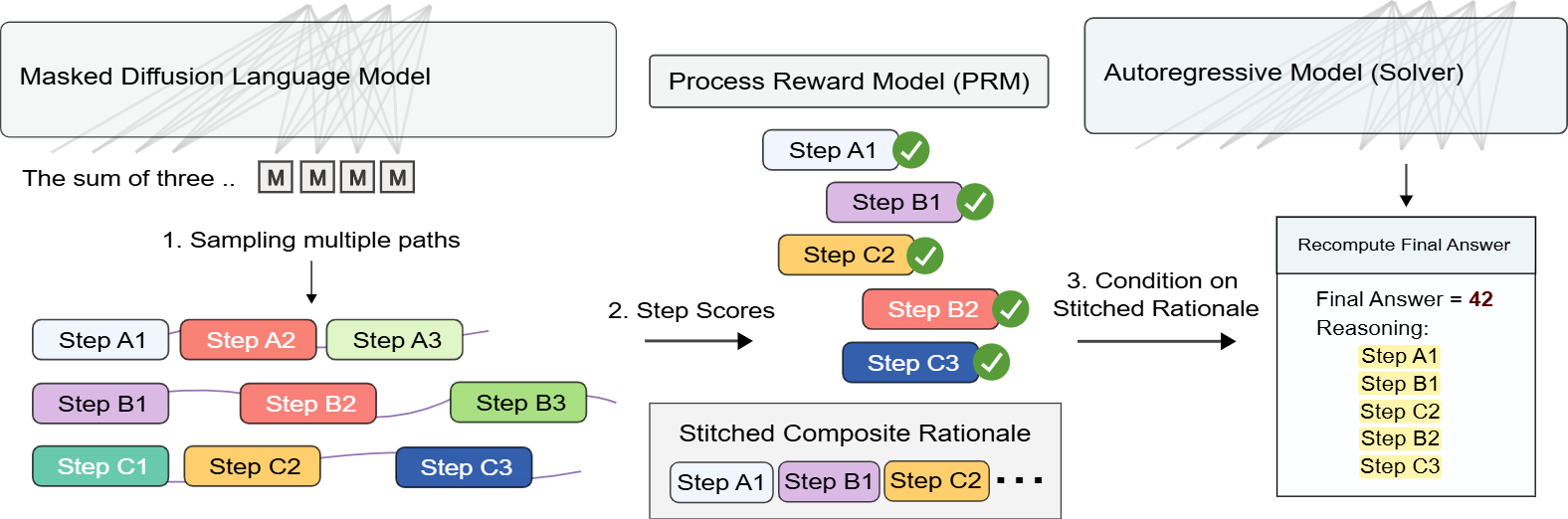
Reward-Guided Stitching turns cheap diffusion-sampled reasoning into a reusable pool of step-level candidates. The method samples diverse trajectories with a masked diffusion language model, scores every intermediate step with an off-the-shelf process reward model, and stitches the highest-quality steps into a composite rationale for a downstream autoregressive solver. Across six math and coding benchmarks, the method improves average accuracy by up to 23.8% while reducing latency by up to 1.8x compared with diffusion and unified baselines.
Method
1
Sample many low-cost reasoning trajectories with a masked diffusion language model to preserve diversity and broaden the search space.
2
Evaluate every intermediate step with a process reward model so promising partial reasoning is kept even when the full trajectory is imperfect.
3
Compose the highest-quality local steps into a stronger rationale, then hand that stitched rationale to an autoregressive solver for the final answer.
Core idea
Trajectory-level voting only decides which full attempt wins. Stitching instead reuses the strongest intermediate reasoning across attempts, letting the system salvage partial progress instead of discarding it.
Evaluation
The released code evaluates reward-guided stitching on both math reasoning and coding tasks. Using the provided generation settings, the repository reports the following performance and average reasoning lengths.
| Dataset | Accuracy | Avg. steps |
|---|---|---|
GSM8K |
91.81% | 108.28 |
MATH |
55.00% | 138.32 |
HumanEval |
73.78% | 447.37 |
HumanEval+ |
70.12% | 447.37 |
MBPP |
73.00% | 188.68 |
MBPP+ |
83.86% | 176.65 |
Citation
@misc{miles2026testtimescalingdiffusionlanguage,
title={Test-Time Scaling with Diffusion Language Models via Reward-Guided Stitching},
author={Roy Miles and Aysim Toker and Andreea-Maria Oncescu and Songcen Xu and Jiankang Deng and Ismail Elezi},
year={2026},
journal={arXiv preprint}
}